





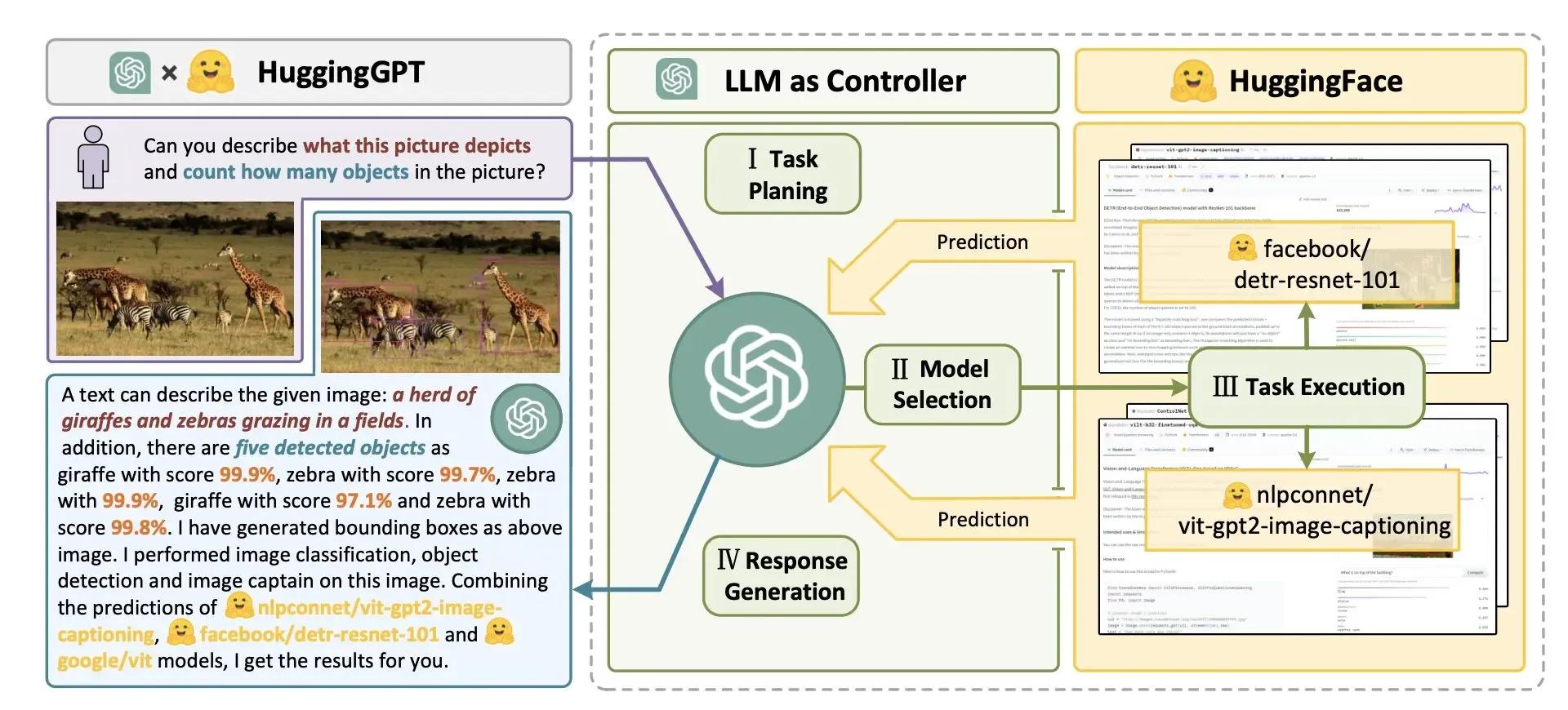
在使用大语言模型(LLM)进行文本二分类时,选择微调基础模型还是聊天模型的效果存在差异。微调基础模型通常专注于具体任务,能够更好地捕捉文本分类的特征,因此在一些专业领域可能表现更优。而微调聊天模型则在理解上下文和生成自然语言方面具有优势,适合需要更复杂对话交互的应用场景。选择哪种方法最优主要取决于具体的应用需求和数据特征。如果任务侧重于高精度分类,基础模型可能更佳;而需要更灵活的交互能力时,聊天模型则可能更合适。
目录导读:
在当今的信息时代,文本数据的爆炸性增长让我们倍感压力,如何从这片浩瀚的信息海洋中快速准确地分类和提取有用的信息,成了许多研究人员和工程师们关心的焦点,而大语言模型(LLM)如火如荼地占据了这一领域,其中基于文本二分类的问题引起了人们的广泛关注,本文将引导您探索“用 LLM 实现文本二分类,微调基础模型还是微调聊天模型比较好?”这个问题,过程中的技术点尽量让人轻松易懂,保证你在阅读过程中不会打瞌睡。
什么是文本二分类?
文本二分类,顾名思义,就是将文本分为两个类别,简单点说,就是把一段文字丢进去,然后告诉计算机:“嘿,这段话是‘正面’的,还是‘负面’的?”想象一下,一个智能分类器、聊天机器人或者情感分析工具,只需通过一个简单的二分类模型,就能给用户提供非常有价值的信息。
文本二分类的具体应用场景非常丰富,比如情感分析、垃圾邮件分类、新闻讨论的定向推荐等等,这里就不一一列举了,分类”在如今的数字生活中可是无处不在!
LLM的崛起
在过去的几年里,LLM的崛起改变了整个自然语言处理(NLP)领域,大语言模型就是像 OpenAI 的 GPT 系列,Google 的 BERT 之类的家伙,它们通过海量数据训练,能够生成连贯、自然的语言,用这些模型进行文本二分类的意义在于,借助其庞大的参数和深厚的文本理解能力,我们可以大幅提高分类的准确率。
面对这些强大的工具,问题自然接踵而来——我应该微调基础模型,还是微调聊天模型来实现文本二分类呢?这个问题可不是简单的“选择 A 还是选择 B”就能解决的,让我们逐步探讨这个问题。
基础模型 vs 聊天模型
在讨论微调之前,首先我们得明确什么是基础模型和聊天模型。
1、基础模型:这是指像 BERT、RoBERTa、DistilBERT 这样的模型,它们经过预训练后,通常具备很强的语言理解能力,但缺乏聊天交互的能力,它们在众多NLP任务上表现优异,包括文本分类、命名实体识别等。
2、聊天模型:如 GPT 系列,它们不仅能够理解文本,还能够生成连贯的自然语言,这些模型的设计初衷是与人进行自然、流畅的交互,尤其在对话场景中表现得尤为出色。
选择哪个模型进行微调呢?当然要考虑到你的具体应用场景啦!这就像买鞋子,有人喜欢登山鞋,有人则想要休闲鞋,两者各有千秋。
微调基础模型的优势
选择微调基础模型的优势主要体现在以下几个方面:
1. 专注于任务
基础模型经过针对NLP任务的训练,所以它们在理解和处理文本方面更为精准,尤其是文本分类类的任务,它们专注于上下文的语义理解,非常适合二分类任务。
2. 参数经济
基础模型通常参数较少,训练和推理速度较快,并且所需的计算资源较少,如果您手边的GPU不多,微调基础模型就是个不错的选择。
3. 转移学习

基础模型可以非常好地进行转移学习,由于这些模型已经在大规模的语料库上进行了预训练,因此再进行微调时,只需要适度训练即可,在一些特定的任务上,它们可以快速收敛。
4. 可解释性
基础模型对于任务的响应比较直接,其决策过程较为容易理解,对于一些需要较高可解释性的应用场景,基础模型可能是更为理想的选择。
微调聊天模型的优势
微调聊天模型也有其独特的优势:
1. 强大的生成能力
聊天模型在文本生成和语言理解方面的能力非常强大,如果你的应用需要生成和理解长文本,或者与用户进行深入的对话,那么聊天模型可能更加合适。
2. 适应多样化的任务
聊天模型可以处理的任务种类较多,从文本分类、对话生成到文本摘要,几乎样样精通,这意味着在某些情况下,你只需一个模型就能解决多个任务,这对开发者来说无疑是个福利。
3. 交互性
聊天模型设计为与人类交互,因此在处理同一上下文中的多轮对话时表现极为出色,如果你的文本分类任务涉及用户反馈或多轮对话的上下文,聊天模型会更为合适。
4. 快速响应
聊天模型一般回应迅速,迭代和微调相对基础模型更加灵活,让开发者可以更快适应实时数据的变化。
选择的关键因素
究竟哪种模型更适合微调来实现文本二分类呢?这得视情况而定,以下几个因素可以作为参考:
1. 数据量
如果你的数据量相对有限,基础模型可能会表现得更好,因为它们已经在许多语言上下文中进行了较好的训练,而对于大型数据集,微调聊天模型的潜力则可能得到更好的发挥。
2. 计算资源
如果你的计算资源有限,基础模型一般而言会更加高效,不过,再有序的微调也可能会使大模型在特定任务上显得不可忽视。
3. 应用场景
如果你的任务需要生成多样化文本或涉及复杂的对话情境,建议优先考虑微调聊天模型;而如果只是需要一个简单的分类结果,基础模型则是更简单直接的选择。
4. 可解释性需求
在一些需要高可解释性的场景,基础模型往往更具优势,而聊天模型则可能因为其生成的多样性而显得不够直观。
实践中的经验教训
在微调模型的时候,总会有一些意想不到的坑等着你跳!来分享一些实践中的经验教训,以便帮助你更好地选择合适的模型。
1. 预先处理数据
不论选择哪个模型,数据预处理都是关键!确保你的文本经过清洗、去噪以及合适的标注是至关重要的。
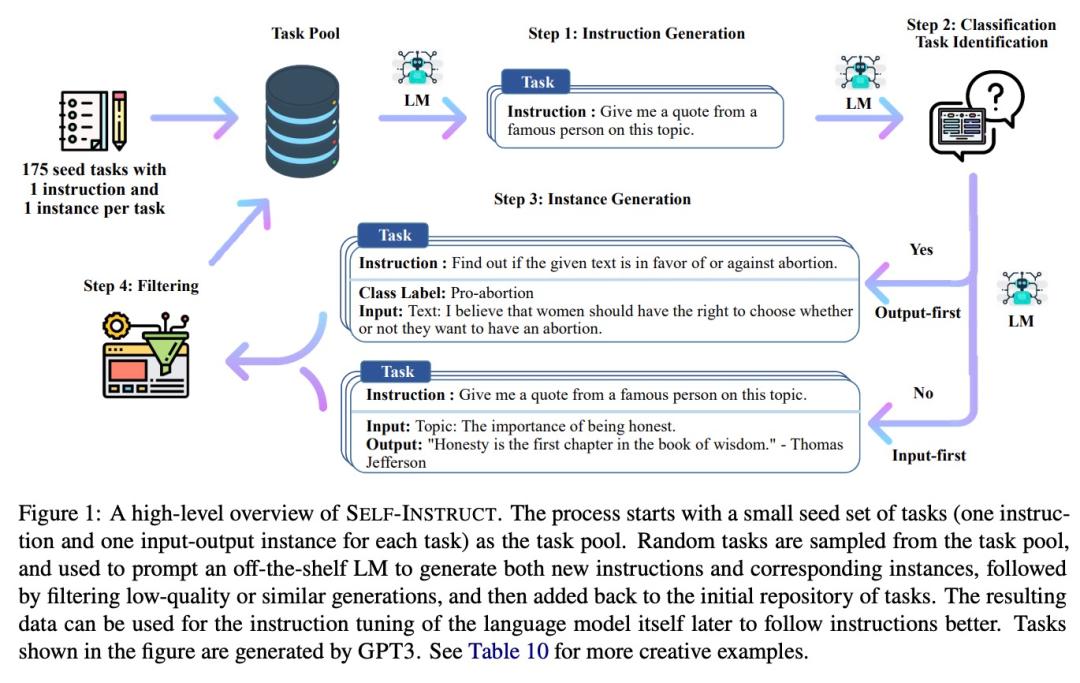
2. 超参数调优
微调的超参数一般需要仔细调节,过高的学习率可能导致模型无法收敛,而过低的学习率又会拖慢训练进程,找到平衡点至关重要。
3. 监控模型表现
随时监控训练过程中模型的表现,包括损失函数和准确率等指标,及时调整策略。
4. 实验性
最好的选择来自实验!试着在同一任务上轮流使用不同的模型,观察各自表现,逐步找到最适合你的方案。
通过以上分析,我们深入探讨了使用 LLM 实现文本二分类时,考虑微调基础模型与聊天模型时的各自优势和不足,究竟该选择哪个模型来进行微调,最终还是得根据具体的应用场景、数据量、计算资源以及对可解释性的需求来做出明智的判断。
无论你是选择基础模型,还是偏爱聊天模型,机器学习技术最核心的目的其实是帮助我们更好地理解和利用数据,从而做出睿智的决策,科学的变化,创新的灵魂,如果你还在犹豫不决,不妨嘲笑一声:“选择困难症,我就是这条鱼!”但与此同时,也要记得三思而后行,选择最适合你需求的工具才是最终目标。
希望以上的讨论对你在 LLM 文本二分类的道路上有所帮助,在数据的海洋中,带着你的模型,顺风而行!
转载请注明来自上海悟真财务咨询有限公司,本文标题:《用 LLM 实现文本二分类,微调基础模型还是微调聊天模型,哪个更好?》







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号