




在当前的人工智能发展中,Scaling Law对模型性能的提升起到了重要作用,但似乎有可能面临瓶颈。随着模型规模不断扩大,性能的边际收益逐渐减少,这引发了对未来发展方向的深入思考。为了突破这一“撞墙”现象,研究者需要探索更有效的基座大模型构建方法,如优化网络架构、引入创新的训练策略、整合多模态数据等。关注模型的可解释性和能效也将为未来的发展提供新的机遇。通过这些努力,可能会找到推动大模型持续进步的新路径。
目录导读:
- 什么是Scaling Law?
- Scaling Law的神奇之处
- Scaling Law的局限性
- 如何避免“撞墙”?
- 基座大模型的未来方向
- Scaling Law的未来探索
- Scaling Law对其他领域的启发
- Scaling Law需要多维度的思考
- Scaling Law与人类智能的关系
在这个技术日新月异的时代,尤其是在人工智能和机器学习的领域,Scaling Law(缩放法则)这个词越来越频繁地出现在我们的视野中,学术界和工业界都对其表现出浓厚的兴趣,Scaling Law真的是我们未来的“金钥匙”吗?或者说,我们是不是要在某个地方“撞墙”了?
我们将深入探讨Scaling Law的内涵,分析其对基座大模型(如GPT系列、BERT等)的影响,同时也探讨未来的大模型发展方向,我将分成一二三四五六七八九十十这十个部分,带你走进Scaling Law的世界!
什么是Scaling Law?
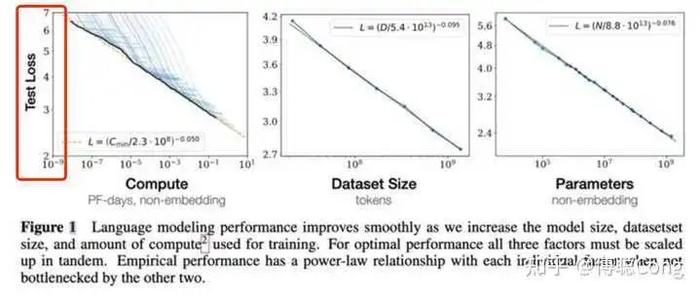
Scaling Law,翻译过来就是“缩放法则”,它的核心概念是:在机器学习中,模型的性能和其规模(包括参数数量、数据量等)之间存在一定的规律,当我们增加模型的规模时,其性能也会随之提高,但这个提升并不是线性的,而是呈现出一定的幂律关系。
在2018年,OpenAI推出的GPT-2模型中,我们首次见识到了Scaling Law的魔力:随着参数数量从117M(百万)增加到1.5B(十亿),模型的性能几乎是成倍提升的,这让我忍不住想问:如果我把参数加到100B,是不是就能实现人工智能的超级智能?
Scaling Law的神奇之处
Scaling Law的魅力在于它为研究者们提供了一条清晰的路线:只要不断地扩大模型规模,就能不断提高模型的性能,这样的想法是不是很让人心动?不过,随着竞争的加剧,我们好像走入了一个“无止境”的模型扩展中,模型越做越大,消耗的计算资源也越来越可观,这样的未来让人感到有些担忧。
想象一下,当模型参数数以百亿计时,训练它所需的算力几乎可以覆盖一个大型数据中心的耗电量,不仅如此,训练这些庞然大物还需要大量的时间和资金,这使得很多小团队和初创企业面临巨大的挑战。
Scaling Law的局限性
Scaling Law并不是没有局限性,虽然我们可以通过增加模型的参数来提升性能,但这种方法在某种程度上会导致“边际效应递减”,也就是说,当模型发展到一定规模后,继续扩大规模所带来的性能提升将会越来越小。
更大的模型并不一定意味着更好的智能,人类的智力是多维度的,仅仅依靠参数规模的增加能否真正模拟人类的复杂思维?这就引出了一个问题:模型的规模不是全部,模型的结构和算法的优化同样重要。
如何避免“撞墙”?
想要找到基座大模型的未来方向,我们需要认真思考如何避免在Scaling Law的“墙”上摔得粉身碎骨,以下是一些可行的策略:
1、探索模型架构的创新:突破传统的Transformer模型设计,寻找更高效、更灵活的神经网络架构,让模型即使在规模较小的情况下也能发挥出更强的性能。
2、强化学习与元学习结合:将强化学习与元学习结合,形成自适应、动态的学习框架,能够让模型在不同任务之间进行更好的迁移和泛化。
3、高效的数据利用:提升数据的利用效率,尤其是小样本学习(few-shot learning)和无监督学习(unsupervised learning)的研究,能够减少对大量标注数据的依赖。
4、模型压缩与蒸馏技术:在大型模型训练完成后,进行模型压缩和蒸馏,让小模型也能具备大模型的能力,这样可以在资源有限的情况下,依然保持优秀的性能。
5、多模态学习:结合视觉、听觉、文本等多种信息源,探索跨模态的学习方法,提升模型对复杂任务的处理能力。
基座大模型的未来方向
随着Scaling Law的深入研究,基座大模型的发展将会朝着几个方向进行演变:
1、可解释性和透明度:未来的大模型需要在性能与可解释性之间找到平衡,如何让机器学习的决策过程变得透明,让用户理解其背后的逻辑,将是一个重要的研究方向。
2、多样性与公平性:大模型的发展也需要关注社会伦理问题,尤其是关于算法的公平性和多样性的问题,如何确保算法不会偏向某些群体,使得人工智能的决策更加公平合理,也是未来的重要任务。
3、节能与环保:在构建大模型的过程中,节能与环保将成为重中之重,研发更高效的算法和低功耗的硬件,将是技术进步的重要方向。
Scaling Law的未来探索
Scaling Law的研究并未停止,我们已经看到越来越多的研究者开始将焦点放在该法则更深层的本质上,有研究者提出在不同领域中,Scaling Law并不总是线性的关系,它可能会随着任务复杂度和模型结构的变化而不同,未来的研究将更多地聚焦于理解Scaling Law的内在机制。
针对当前对大模型训练需要大量计算资源的问题,很多团队开始探索“友好的AI”的概念,尝试在保证模型能力的同时,减少对资源的依赖,以期实现社会效益与经济效益的双重收获。
Scaling Law对其他领域的启发
除了在自然语言处理领域的广泛应用,Scaling Law的思想也渗透到了其他许多领域,比如计算机视觉、图像生成等,通过不断增加模型规模和数据量,这些领域的研究者们同样获得了显著的性能提升。
在计算机视觉中,卷积神经网络(CNN)在越来越大的数据集上进行训练,表明Scaling Law同样适用于图像识别、目标检测等任务,这为其他领域的研究者提供了新的思路,也为跨领域的研究合作提供了可能。
Scaling Law需要多维度的思考
面对Scaling Law,我们需要更广阔的视野,深入探讨“什么样的模型结构在特定大小下能够取得最佳表现?”等问题,跨学科的合作也是至关重要的,物理学、复杂系统科学等领域的理论也许能为我们的Scaling Law研究提供新的视角。
为了避免“撞墙”,我们需要继续推动基础研究,重视理论与实践的结合,鼓励创新思维,在Scaling Law的指导下,探讨具有更高效率和更低成本的模型训练方式,将是未来研究的重要方向。
Scaling Law与人类智能的关系
一个让人充满好奇的问题是,Scaling Law和人类智能之间到底有什么联系?我们在构建大规模模型时,是否有可能真正模拟人类的思维过程?
目前,科学家们对人类思维的理解仍然十分有限,尽管我们可以通过算法设计来试图模拟某种思维,但事实上,人的智慧是多维度的,涉及情感、道德、伦理等多方面因素,未来的发展应该不仅限于数字和算法,还要更加关注人类层面的问题。
Scaling Law在人工智能模型的发展中展现出巨大的潜力,它提示我们模型规模与性能之间的奇妙关系,我们也必须正视Scaling Law的局限性和可能面临的挑战。
针对Scaling Law带来的“撞墙”风险,研究者们必须在模型结构、算法优化以及社会伦理方面进行多方位的探索,未来的基座大模型不再仅仅是简单的参数累加,它将更加关注如何在合理的资源使用下,创造出真正有用的智能。
在这条AI的路上,Scaling Law 只是我们前行的起点,真正的未来在探求、在创新、在每一次的反思与实践中不断演进,相信在不久的将来,借助Scaling Law的力量,我们将能够开创一个更加美好的人工智能新时代!
转载请注明来自上海悟真财务咨询有限公司,本文标题:《Scaling Law,要撞墙了吗?如何找到基座大模型的未来方向?》





 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号